Node Extraction
This guide show you shows how nodes can be used to work generically with document contents to find and copy contents across files.
Before you begin
You should get your API key from your UniCloud account.
If this is your first time using UniOffice SDK, follow this guide to set up a local development environment.
Clone the project repository
In your terminal, clone the examples repository. It contains the Go code we will be using for this guide.
git clone https://github.com/unidoc/unioffice-examples
To get the example navigate to the path document/node-extraction folder in the unioffice-examples directory.
cd unioffice-examples/document/node-extraction/
These are the images of the file that will be used for this example:
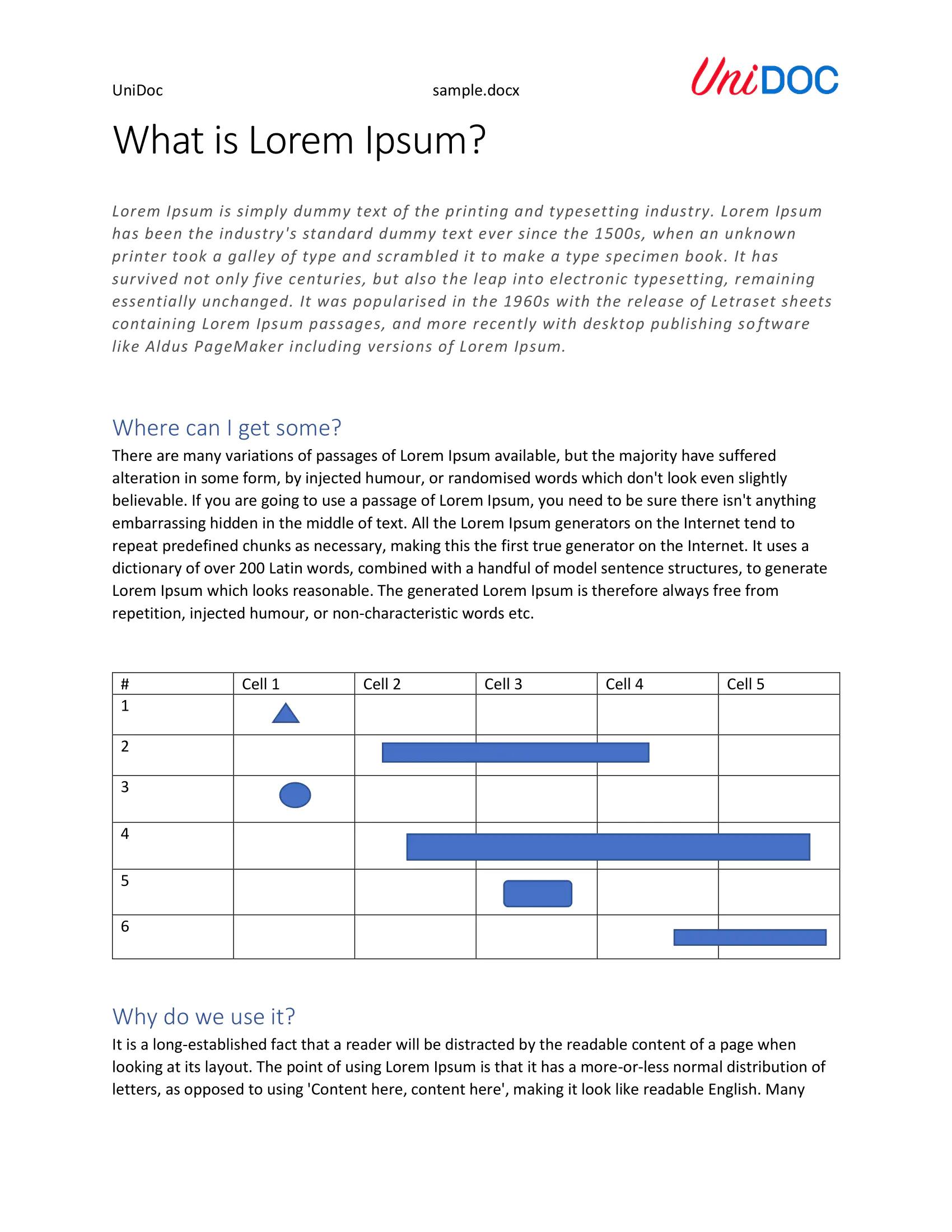


How it works
Lines 13-20 import the UniOffice packages and other required dependencies.
The init function in lines 22-29 authenticates your request with your UNIDOC_LICENSE_API_KEY.
In the main function, spanning lines 31-83, the process begins with the opening of the sample document. At line 39, the Nodes function is employed to retrieve all elements within the file as nodes. Subsequently, two texts within the nodes are replaced with different content at lines 42 and 43.
Additionally, at line 46, a demonstration is provided on how specific nodes can be obtained based on their style, specifically, nodes with a heading 1 style. These nodes are iterated through, creating a new document for each node with that particular style.
Following this, between lines 56 and 75, all nodes in the document are iterated through within another loop. This process starts from the initial nodeParent and continues until the next nodeParent is encountered. While the next identified node is not a nodeParent, these nodes are added to the document of the current nodeParent. If another nodeParent is discovered, the loop that traverses all nodes is terminated, and the generated file is saved. Subsequently, the process returns to the beginning of the nodeParents loop to create a new document for the next node.
Run the code
Run this command to perform node extraction.
go run main.go
Sample output
Here is the first document created:
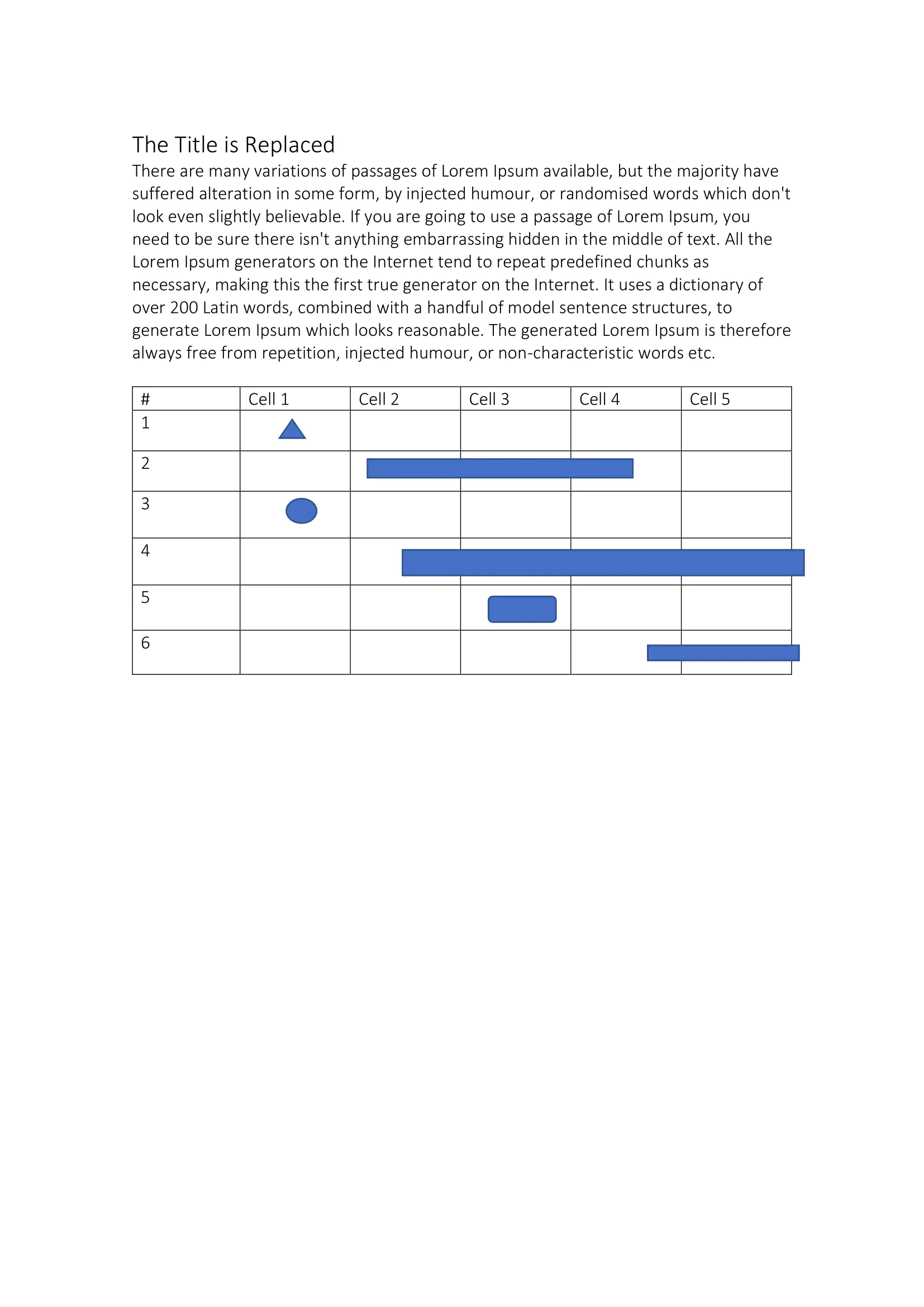
And this is the second document that is created:

