Font Extraction
This guide will show you how to use the extractor package to extract font(s) from a specific page in a PDF and save the output font(s) to a zip archive.
Sample input

Before you begin
You should get your API key from your UniCloud account.
If this is your first time using UniPDF SDK, follow this guide to set up a local development environment.
Project setup
Clone the project repository
In your terminal, clone the examples repository. It contains the Go code we will be using for this example.
git clone https://github.com/unidoc/unipdf-examples.git
Navigate to the extract folder in the unipdf-examples directory.
cd unipdf-examples/extract
How it works
Lines 3-12 import the UniPDF packages and other required dependencies.
Lines 14-21 authenticate your request with your UNIDOC_LICENSE_API_KEY with the init function.
The main function in lines 22-52 validates your input and passes it as arguments to the extractFontToArchive function.
Lines 55-131 define the extractFontToArchive function, accepting the inputPath, outpathPath, and pageNumber as arguments. The extractor package extracts the font(s) for the specified page in the input PDF, saves the fonts in the output path as a zip archive, and prints the font properties to the terminal.
Run the code
Run this command to extract text from each page in the PDF. This will also get all the required dependencies to run the program.
# setting page number to 0 extract the fonts for all the pages in the PDF.
# extracting fonts for page 4
go run pdf_extract_fonts.go input.pdf <pagenumber> output.zip
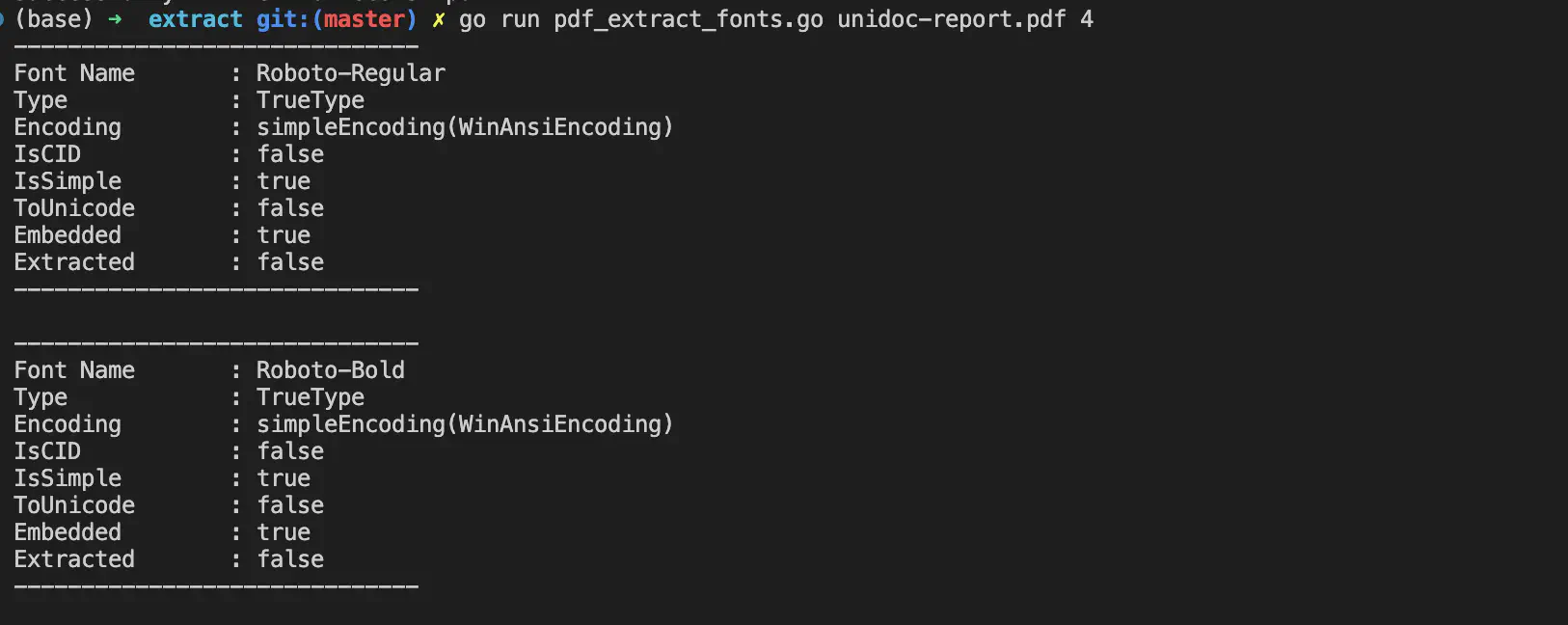
Sample output
You will get the font(s) for the specified page in the PDF as a zip archive. Unzip the file to see its content.